Vision-Language Models such as CLIP exhibit strong zero-shot recognition capability by
aligning images with textual concepts, yet they often underperform on multi-label
recognition where multiple objects co-exist. A key bottleneck is that the [CLS] token, as a single global visual
representation, is insufficient to faithfully encode diverse targets with varying
scales, contexts, and co-occurrence patterns.
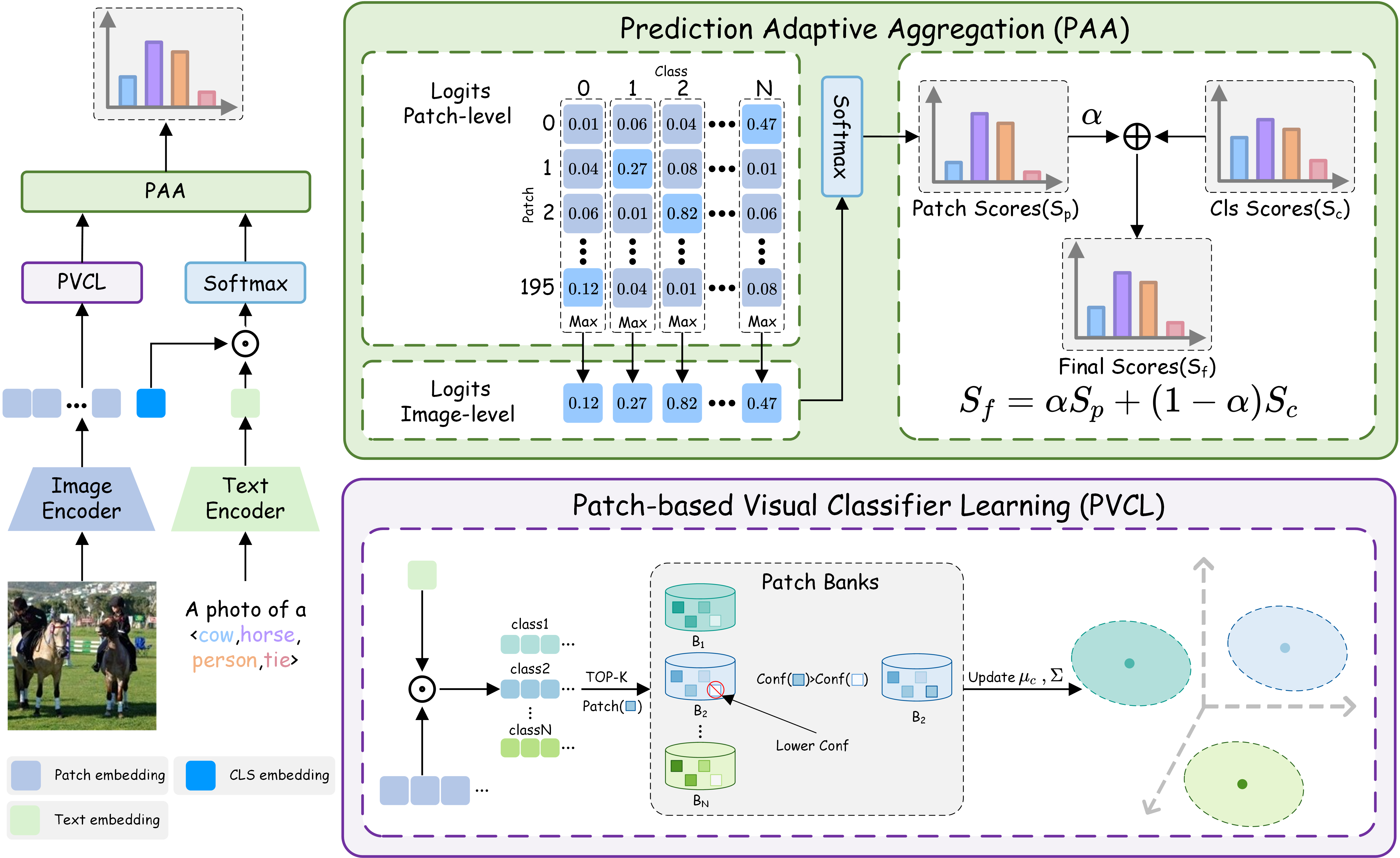
To address this limitation, we present a new multi-label image recognition framework,
termed PIAA, which formulates prediction as
Patch-level Inference followed by
Adaptive Aggregation. Specifically, we first
enhance patch-wise predictions from two complementary perspectives: (i) mitigating
semantic entanglement in the visual encoder to obtain more discriminative patch
representations, and (ii) learning an unsupervised visual classifier to narrow the
vision–language modality gap.
We then introduce an adaptive aggregation module that consolidates patch-level scores
into the final multi-label prediction. Notably, the entire pipeline is fully
training-free, requiring no gradient updates or parameter fine-tuning.
Experiments show that our method achieves strong improvements with minimal extra
computation, exceeding a 6% mAP gain on the challenging NUS-WIDE benchmark over
representative baselines.